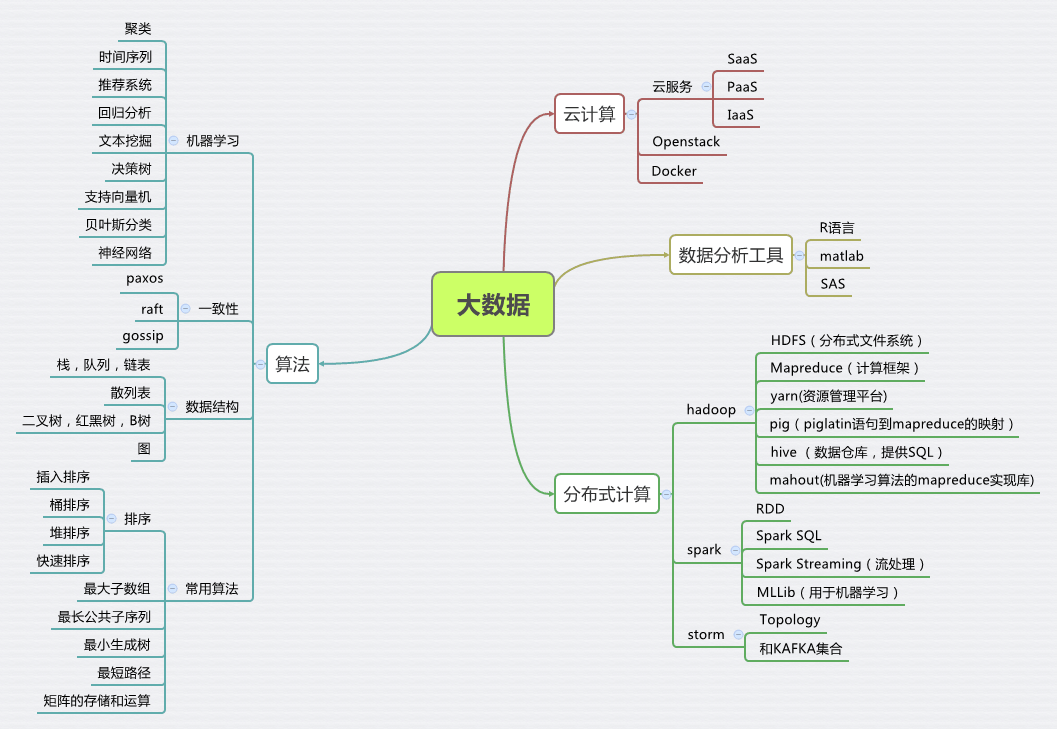
大数据知识图谱
分布式计算
经典计算模型MapReduce
MapReduce论文
MapReduce编程
基于 MapReduce 的并行计算框架
开源计算框架
hadoop
Apache Hadoop 是用于开发在分布式计算环境中执行的数据处理应用程序的框架。类似于在个人计算机系统的本地文件系统的数据,在 Hadoop 数据保存在被称为作为Hadoop分布式文件系统的分布式文件系统。处理模型是基于“数据局部性”的概念,其中的计算逻辑被发送到包含数据的集群节点(服务器)。这个计算逻辑不过是写在编译的高级语言程序,例如 Java. 这样的程序来处理Hadoop 存储 的 HDFS 数据。
Hadoop是一个开源软件框架。使用Hadoop构建的应用程序都分布在集群计算机商业大型数据集上运行。商业电脑便宜并广泛使用。这些主要是在低成本计算上实现更大的计算能力非常有用。计算机集群由一组多个处理单元(存储磁盘+处理器),其被连接到彼此,并作为一个单一的系统。
spark
Spark是基于内存计算的大数据并行计算框架.Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量的廉价硬件之上,形成集群。
Spark是MapReduce的替代方案,而且兼容HDFS、Hive等分布式存储层,可融入
Hadoop的生态系统,以弥补缺失MapReduce的不足
kafka
Apache Kafka发源于LinkedIn,于2011年成为Apache的孵化项目,随后于2012年成为Apache的主要项目之一。Kafka使用Scala和Java进行编写。Apache Kafka是一个快速、可扩展的、高吞吐、可容错的分布式发布订阅消息系统。Kafka具有高吞吐量、内置分区、支持数据副本和容错的特性,适合在大规模消息处理场景中使用。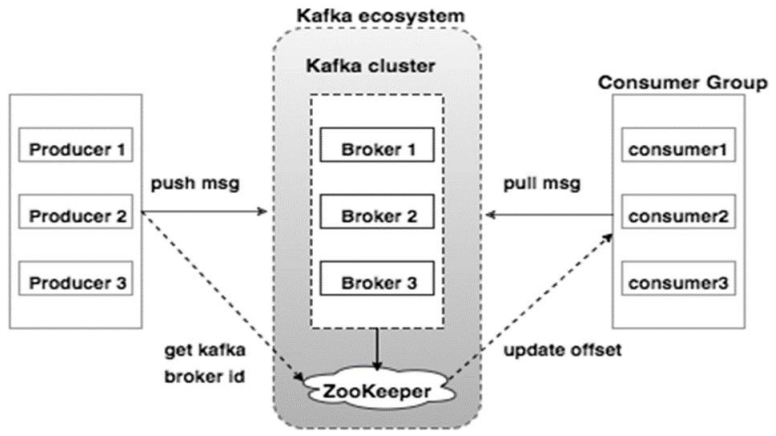
生产者消费者模型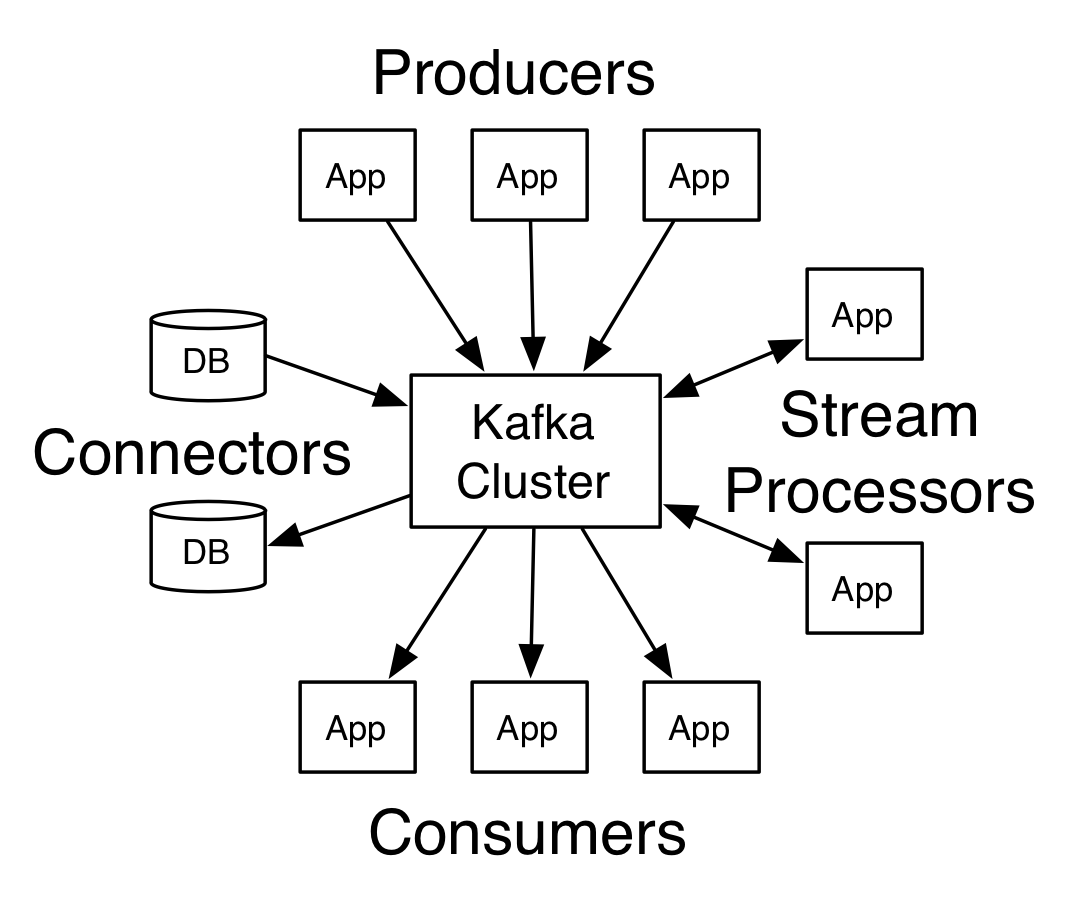
Apache kafka 工作原理介绍
Kafka快速开始(官方良心文档,最快的方式知道kafka是什么,它在干什么)
Kafka生产者编程
Kafka生产者编程
Kafka消费者编程
Kafka消费者编程
Kafka流式计算API
Storm
Apache Storm是一种侧重于极低延迟的流处理框架,也许是要求近实时处理的工作负载的最佳选择。该技术可处理非常大量的数据,通过比其他解决方案更低的延迟提供结果。
Storm 顶级抽象图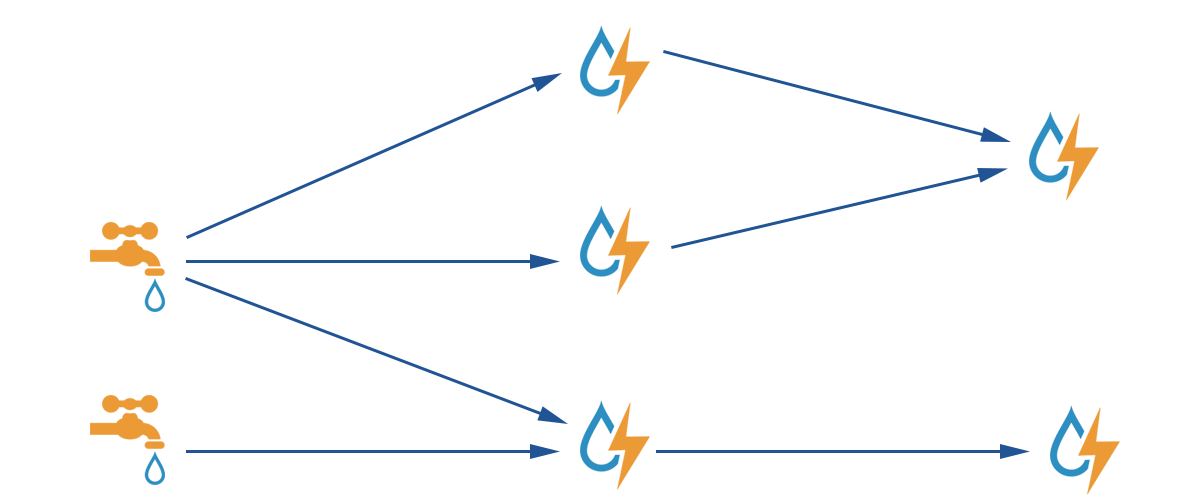

Storm官方概念
Storm官方实例代码
Storm示例代码
Storm优秀博客
工作室产出文章
hadoop安装http://fenlan.github.io/2017/09/22/hadoop/#more
Kafka安装http://fenlan.github.io/2017/11/29/zookeeper-kafka/#more