static和final的区别和用途
Static
- 修饰变量:静态变量随着类的加载时完成初始化,内存中只有一个,且JVM也只会为他分配一次内存,所有类共享静态变量,静态变量放在指定的静态共享区,遵循一改全改。
- 修饰方法:静态方法在类加载时就存在与静态区域,不依赖任何实例,Static方法必须实现,不能是抽象类abstract。使用静态方法时可以直接使用
类名.方法名,不需要实例化一个对象。 - 修饰代码块:类加载完后执行代码块中的内容。
Final
- 修饰变量:
- 编译时常量:类加载的过程完成初始化,编译后带入到任何计算式中,只能是基本类型。
- 运行时常量:基本数据类型或引用数据类型,引用不可变,但引用的内容可以变。
- 修饰方法:跟final单词意思相近,最后的方法,表示不能被继承,不能被子类修改重写。
- 修饰类:不能被继承。
- 修饰形参:final形参在方法内不可变。
- 修饰变量:
1 | class Value { |
同步机制实现原子化 synchronized
丢失更新(lost update) 有一种特定的过程。
(1) 取得账户余额。int i = balance;
(2) 将账户余额加1。balance = i + 1;
这会让计算机以两个步骤来完成账户的变化。通常我们会以单一的命令来做这件事情:balance++;
但强行以两个步骤来处理就会浮现出非原子性的问题。下面用两个都想把余额递增的线程来展示丢失更新。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class TestSync implements Runnable {
private int balance;
/** 每个线程都把账户递增50次 **/
public void run() {
for(int i = 0; i < 50; i++) {
increament();
System.out.println("balance is " + balance);
}
}
private void increament() {
int i = balance;
/** 问题出在我们用的是读取的值而不是目前的值 **/
balance = i + 1;
}
}
public class TestSyncTest {
public static void main(String[] args) {
TestSync job = new TestSync();
Thread a = new Thread(job);
Thread b = new Thread(job);
a.start();
b.start();
}
}
用同步机制让increment() 方法原子化,将increment()方法同步化可以解决丢失更新的问题,因为他会让方法中的两个步骤组成不可分割的单元。1
2
3
4private synchronized void increment() {
int i = balance;
balance = i + 1;
}
但同步化是需要付出额外的成本。也就是说进入同步化方法的程序会查询钥匙等性能上的损耗。其次,同步化的方法会让你的程序因为要同步并行的问题而慢下来。同步化会强制线程排队等待执行方法。最后,最可怕的是同步化可能会导致死锁现象。原则上最好制作最少量的同步化。事实上同步化的规模可以小于方法全部,可以用synchronized来修饰一行或数行的代码而不必整个方法都同步化。比如:1
2
3
4
5
6
7
8public void go() {
doStuff();
synchronized(this) {
criticalStuff();
moreCriticalStuff();
}
}
并行问题也是线程安全的问题,对于一个类是否线程安全,重要的决定因素便是是否存在上面提及的问题,诸如HashMap和HashTable、StringBuffer和StringBuiler、Vector和ArrayList等的区别,其中HashMap、StringBuiler、ArrayList没有实现同步化,因此是非线程安全的;HashTable、StringBuffer、Vector在原本HashMap、StringBuiler、ArrayList的方法上添加了synchronized修饰来保证线程安全。
hashCode()与equals()的相关规定
API文件有对对象的状态指定出必须遵守的规则:
- 如果两个对象相等,则
hashcode必须也是相等的。 - 如果两个对象相等,对其中一个对象调用
equals()必须返回true。也就是说,若a.equals(b)则b.equals(a)。 - 如果两个对象有相同的
hashcode值,它们也不一定是相等的。但若两个对象相等,则hashcode值一定是相等的。 - 因此若
equals()被覆盖过,则hashCode()也必须被覆盖。 hashCode()的默认行为是对在heap(堆)上的对象产生独特的值。如果你没有override过hashCode(),则该class的两个对象怎样都不会被认为是相同的。equals()的默认行为是执行==的比较。也就是说会去测试两个引用是否对上heap上同一个对象。如果equals()没有被覆盖过,两个对象永远都不会被视为相同的,因为不同的对象有不同的字节组合。
a.equals(b)必须与a.hashCode() == b.hashCode()等值。但a.hashCode() == b.hashCode()不一定要与a.equals()等值。
问:为什么不同对象会有相同hashcode的可能
答:HashSet使用hashcode来达成存取速度较快的存储方法。如果你尝试用对象来寻找ArrayList中相同的对象(也就是不用索引来找),ArrayList会从头开始找起。但是HashSet这样找对象的速度就块多了,因为它使用hashcode来寻找符合条件的元素。因此当你想要寻找某个对象时,通过hashcode就可以很快算出该对象所在的位置,而不用从头一个一个找起。重点在于hashcode相同并不一定保证对象是相等的,因为hashCode()所使用的杂凑算法也许刚刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特征有关。如果HashSet发现在对比的时候,同样的hashcode有多个对象,它会使用equals()来判断是否有完全的符合。也就是说,hashcode是用来缩小寻找成本,但最后还是要用equals()才能认定是否真的找到相同的项目。
这与加密中的问题一样,网络中将用户的密码获取后,通过加密算法将密码加密成一个固定长度的无规律字符串保存在数据库中,密码相同,肯定加密的结果是唯一相同的,但是由于加密过后是固定长度,比如32个字节,那么着32个字节就有固定的容量,因此会出现两个不同的密码加密后是一样的字符串。
对于上述第四条和第五条,个人的理解是:hashCode()方法原本是根据对象在内存中的位置来计算,因此如果要比较两个对象是否相等,通过原本的hashCode()方法计算会得到两个不同的值,因为是两个对象,原本的hashCode()是一个对象对应一个唯一的值,这个值与内存位置有关,而两个对象是在不同的内存位置上,如果强行想要表示这两个对象相等,就必须重写原本的hashCode()。
同样的,对于equals()方法,原本是表示两个引用所指向的对象是否是一个对象,但是我们需要按照自己的意愿去表示两个不同的对象,如果某些特征相同时也表示相等,比如想要表示一个人的信息,在不同时间点记录的信息会不同,但只要身份证号一样,我们就认为这是同一个人。这就需要重写equals()方法,让它表示两个不同对象在意义上相同。
综合上述的描述 : hashCode()是判断引用相等,equals()是判断对象相等。
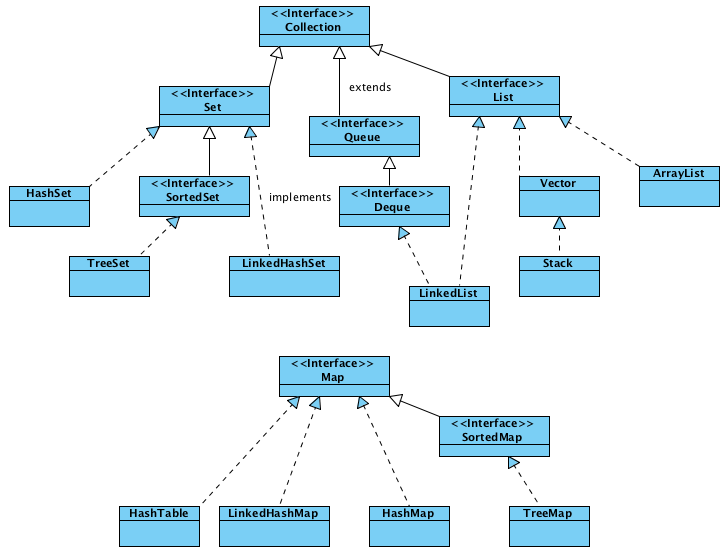
Collection API
多线程
Java实现多线程的方式
- 继承
Thread类,重写run方法 - 实现
Runable接口 - 实现
Callable接口
启动多线程时,
start()方法的调用后并不是立即执行多线程代码,而是使得该线程变为可运行态(Runnable),什么时候运行是由操作系统决定的。
从程序运行的结果可以发现,多线程程序是乱序执行。因此,只有乱序执行的代码才有必要设计为多线程。
Thread.sleep()方法调用目的是不让当前线程独自霸占该进程所获取的CPU资源,以留出一定时间给其他线程执行的机会。
实际上所有的多线程代码执行顺序都是不确定的,每次执行的结果都是随机的。实际上所有的多线程代码都是通过运行Thread的start()方法来运行的。因此,不管是扩展Thread类还是实现Runnable接口来实现多线程,最终还是通过Thread的对象的API来控制线程的。
三种方式的区别
- 实现
Runable接口能增强程序的健壮性,代码能够被多个线程共享,代码与数据是独立的,适合多个相同程序代码的线程区处理同一资源。正如上述同步化所用的程序。 - 继承
Thread类不适合资源共享,但继承Thread和实现Runable都是通过start()启动线程,然后JVM将线程放到就绪队列中,如果有处理机可用,则执行run方法。 - 实现
Callable接口要实现call方法,并且线程执行完后是后返回值的,其他两种都没有返回值。
在java中,每次程序运行至少启动2个线程。一个是main线程,一个是垃圾收集线程。
线程状态

- 新建状态(New):新创建了一个线程对象。
- 就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start()方法。该状态的线程位于可运行线程池中,变得可运行,等待获取CPU的使用权。
- 运行状态(Running):就绪状态的线程获取了CPU,执行程序代码
- 阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
- 等待阻塞:运行的线程执行wait()方法,JVM会把该线程放入等待池中。(wait会释放持有的锁)
- 同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池中。
- 其他阻塞:运行的线程执行sleep()或join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。(注意,sleep是不会释放持有的锁)
- 死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
线程调度
Java线程有优先级,优先级高的线程会获得较多的运行机会。
Java线程的优先级用整数表示,取值范围是1~10,Thread类有以下三个静态常量:1
2
3
4
5
6static int MAX_PRIORITY
线程可以具有的最高优先级,取值为10。
static int MIN_PRIORITY
线程可以具有的最低优先级,取值为1。
static int NORM_PRIORITY
分配给线程的默认优先级,取值为5。
Thread类的setPriority()和getPriority()方法分别用来设置和获取线程的优先级。
每个线程都有默认的优先级。主线程的默认优先级为Thread.NORM_PRIORITY。
线程的优先级有继承关系,比如A线程中创建了B线程,那么B将和A具有相同的优先级。
常用的调度
- 线程睡眠:Thread.sleep(long millis)方法,使线程转到阻塞状态。millis参数设定睡眠的时间,以毫秒为单位。当睡眠结束后,就转为就绪(Runnable)状态。sleep()平台移植性好。sleep不会释放持有的锁。
- 线程等待:Object类中的wait()方法,导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 唤醒方法。这两个唤醒方法也是Object类中的方法,行为等价于调用 wait(0) 一样。wait会释放持有的锁。
- 线程让步:Thread.yield() 方法,暂停当前正在执行的线程对象,把执行机会让给相同或者更高优先级的线程。
- 线程加入:join()方法,等待其他线程终止。在当前线程中调用另一个线程的join()方法,则当前线程转入阻塞状态,直到另一个进程运行结束,当前线程再由阻塞转为就绪状态。
- 线程唤醒:Object类中的notify()方法,唤醒在此对象监视器上等待的单个线程。如果所有线程都在此对象上等待,则会选择唤醒其中一个线程。选择是任意性的,并在对实现做出决定时发生。线程通过调用其中一个 wait 方法,在对象的监视器上等待。 直到当前的线程放弃此对象上的锁定,才能继续执行被唤醒的线程。被唤醒的线程将以常规方式与在该对象上主动同步的其他所有线程进行竞争;例如,唤醒的线程在作为锁定此对象的下一个线程方面没有可靠的特权或劣势。类似的方法还有一个notifyAll(),唤醒在此对象监视器上等待的所有线程。
常用函数说明
sleep(long millis):运行–>阻塞,在指定的毫秒数内让当前正在执行的线程休眠(暂停执行)join():运行–>阻塞,在很多情况下,主线程生成并起动了子线程,如果子线程里要进行大量的耗时的运算,主线程往往将于子线程之前结束,但是如果主线程处理完其他的事务后,需要用到子线程的处理结果,也就是主线程需要等待子线程执行完成之后再结束,这个时候就要用到join()方法了。yield():运行–>可运行,让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会。因此,使用yield()的目的是让相同优先级的线程之间能适当的轮转执行。但是,实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。wait():Obj.wait(),与Obj.notify()必须要与synchronized(Obj)一起使用,也就是wait,与notify是针对已经获取了Obj锁进行操作,从语法角度来说就是Obj.wait(),Obj.notify必须在synchronized(Obj){…}语句块内。从功能上来说wait就是说线程在获取对象锁后,主动释放对象锁,同时本线程休眠。直到有其它线程调用对象的notify()唤醒该线程,才能继续获取对象锁,并继续执行。相应的notify()就是对对象锁的唤醒操作。但有一点需要注意的是notify()调用后,并不是马上就释放对象锁的,而是在相应的synchronized(){}语句块执行结束,自动释放锁后,JVM会在wait()对象锁的线程中随机选取一线程,赋予其对象锁,唤醒线程,继续执行。这样就提供了在线程间同步、唤醒的操作。Thread.sleep()与Object.wait()二者都可以暂停当前线程,释放CPU控制权,主要的区别在于Object.wait()在释放CPU同时,释放了对象锁的控制
wait()和notify()
- wait() 与 notify/notifyAll() 是Object类的方法,在执行两个方法时,要先获得锁。
- 当线程执行wait()时,会把当前的锁释放,然后让出CPU,进入等待状态。
- 当执行notify/notifyAll方法时,会唤醒一个处于等待该 对象锁 的线程,然后继续往下执行,直到执行完退出对象锁锁住的区域(synchronized修饰的代码块)后再释放锁。
synchronized 和lock
synchronized: 在资源竞争不是很激烈的情况下,偶尔会有同步的情形下,synchronized是很合适的。原因在于,编译程序通常会尽可能的进行优化synchronize,另外可读性非常好,不管用没用过5.0多线程包的程序员都能理解。lock(ReentrantLock): 提供了多样化的同步,比如有时间限制的同步,可以被Interrupt的同步(synchronized的同步是不能Interrupt的)等。在资源竞争不激烈的情形下,性能稍微比synchronized差点点。但是当同步非常激烈的时候,synchronized的性能一下子能下降好几十倍。而ReentrantLock确还能维持常态。
Java中的BIO、NIO、AIO
BIO(Blocking I/O): 同步阻塞IO,服务器中一个连接一个线程,数据的读取和写入必须阻塞在一个线程内等待其完成。NIO(New I/O): 同步非阻塞IO,服务器中一个请求一个线程,客户端所有连接注册到多路复用器中,多路复用器轮询所有连接,当存在连接有IO请求时才启动一个线程去处理IO。AIO(Asynchronous I/O): 异步非阻塞IO,服务器中一个有效请求一个线程,没有多路复用器轮询,客户端有IO请求给服务器,服务器获得请求后,由OS处理请求,处理完成后,再通知服务器创建一个线程去处理IO结果。
同步与异步
同步与异步是针对应用程序与内核的交互而言的。同步过程中进程触发IO操作并等待或者轮询的去查看IO操作是否完成。异步过程中进程触发IO操作以后,直接返回,做自己的事情,IO交给内核来处理,完成后内核通知进程IO完成。
阻塞与非阻塞
简单理解为需要做一件事能不能立即得到返回应答,如果不能立即获得返回,需要等待,那就阻塞了,否则就可以理解为非阻塞
未具体理解
匿名内部类
匿名内部类也就是没有名字的内部类
正因为没有名字,所以匿名内部类只能使用一次,它通常用来简化代码编写
但使用匿名内部类还有个前提条件:必须继承一个父类或实现一个接口1
2
3
4
5
6
7
8
9
10
11
12public class AnonymousClass {
public static void main(String[] args) {
Runnable x = new Runnable() {
public void run() {
System.out.println(this.getClass());
}
};
x.run();
}
}
匿名内部类的特征
- 匿名内部类没有访问修饰符(如
public、private) - 当所在方法的形参被匿名内部类使用时,这个行参必须final
- 匿名内部类没有构造方法,因为它连名字都没有
重点解释第二点:
首先我们知道在内部类编译成功后,它会产生一个class文件,该class文件与外部类并不是同一class文件,仅仅只保留对外部类的引用。当外部类传入的参数需要被内部类调用时,从java程序的角度来看是直接被调用:1
2
3
4
5
6
7
8
9
10
11public class AnonymousClass {
public void anonyFinal(String name) {
Runnable x = new Runnable() {
public void run() {
System.out.println(this.getClass() + " " + name);
}
};
x.run();
}
}
从上面代码中看好像name参数应该是被内部类直接调用?其实不然,在java编译之后实际的操作如下:1
2
3
4
5
6
7
8public class AnonymousClass$InnerClass {
public InnerClass(String name) {
this.InnerClass$name = name;
}
public void run() {
System.out.println(this.getClass() + " " + this.InnerClass$name);
}
}
从这里可以看出匿名内部类并不是直接调用行参,而是临时产生构造函数,并将行参引用赋给自己的内部变量,并调用内部变量。因此为了让程序员产生这样的直接调用错觉,规定行参必须是final不可更改的。