索引
顺序索引
聚集索引: 如果包含记录的文件按照某个搜索码指定的顺序排序,那么该搜索码对应的索引称为聚集索引。非聚集索引: 搜索码指定的顺序与文件中记录的物理顺序不同的索引称为非聚集索引。
诸如在大学教师记录文件中,用教师ID作为搜索码,记录按照该搜索码顺序存放。
稠密索引(dense index) : 在稠密索引中,文件中的每一个搜索码值都有一个索引项。在稠密聚集索引中,索引项包括搜索码值以及指向具有该搜索码的第一条数据记录的指针。具有相同搜索码值的其余记录顺序地存储在第一条数据记录之后,由于该索引是聚集索引,因此记录根据相同的搜索码值排序。而在稠密非聚集索引中,索引必须存储指向所有具有相同搜索码值的记录项的指针列表。
稠密聚集索引具有相同搜索码值的记录按照指定顺序存储;但是稠密非聚集索引必须存储指向一个指针列表,这个列表里面有具有相同搜索码值的记录指针。聚集索引只存储第一条记录的指针,其他的按照顺序查找,非聚集索引就要记录一个指针表。

稀疏索引(sparse index): 在稀疏索引中,只为搜索码的某些值建立索引索引项。只有当记录按照搜索码排列顺序存储时才能使用稀疏索引,也就是说,只有索引是聚集索引时才能使用稀疏索引。和稠密索引一样,每个索引项也包括一个搜索码值和指向该搜索码值的第一条记录的指针。为了定位一条记录,我们获取查询记录的搜索码值,再比较索引项中等于或者小于其搜索码值的最大项,然后从该索引项指向的记录开始,沿着文件中的指针查找,直到找到所需记录为止。

就像图中,索引项中没有为每个搜索码(即右边表格中第二列)设立索引项,但这需要保证这些记录按照搜索码顺序排列才行。
多级索引:在外层构建稀疏索引,通过二分查找找到外层索引,外层索引指向内层索引表,内层索引表再找到指定的索引项,最后去定位到记录。
辅助索引: 按聚集索引顺序对文件进行顺序扫描是非常有效的,因为文件中记录的物理存储顺序和索引顺序一致。但是当我们新建立一个索引,而这个索引的顺序跟记录的物理存储顺序不一致时,我们就需要一个辅助索引,这个辅助索引指向每一条记录,这个辅助索引的顺序跟我们要新建的索引顺序一致。
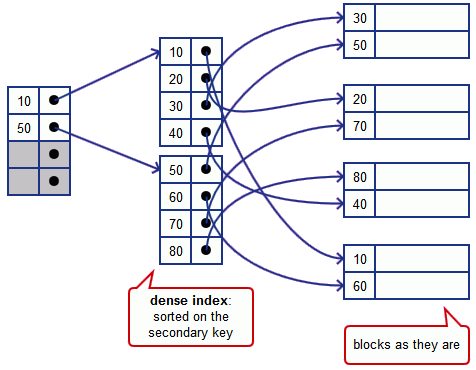
从图里面可以看到,我们新建的索引跟blocks的物理存储顺序不一致,为了解决这个问题,中间添加一个辅助索引,这个辅助索引是稠密索引,同时也根据我们新建索引的顺序进行排序。
B+树索引

索引顺序文件组织的最大缺点在于,随着文件的增大,索引查找性能和数据顺序扫面性能都会下降。虽然这种性能下降可以通过对文件进行重新组织来弥补,但是我们不希望频繁地进行重组。
B+树(B+ -tress)索引结构是在数据插入和删除的情况下仍能保持其执行效率的几种使用最广泛的索引结构之一。B+树索引采用平衡树结构,其中树根到树叶的每条路径的长度相同。树中每个非叶子节点有n/2~n个子女,其中n对特定的树是固定的。
B+树索引是一种多级索引,但是其结构不同与多级索引顺序文件。典型的B+树结点结构如下 :
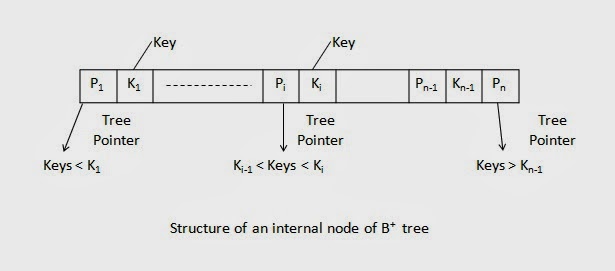
这是内部结点结构
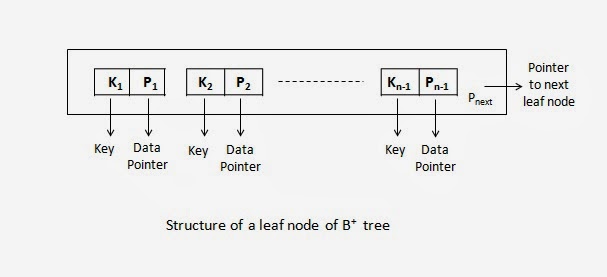
这是叶子结点结构,其中key都表示搜索码值,而叶子节点的指针是指向记录块(或者是记录行),而内部结点是指向下一层的结点。
注意到叶子结点只使用了n-1个指针来指向记录,最后一个指针指向自己的兄弟结点,即下一个叶子节点,这样是为了将所有的叶子节点串起来,这样可以发现从最左边的节点开始,可以按照搜索码顺序遍历所有记录行,这为按顺序查找所有记录的SQL语句提供了更加高效的方式。
B树索引

B树索引和B+树索引相似。两种方法的主要区别在于B树去除了搜索码值存储中冗余。在上面展示的B+树索引中可以看到搜索码3在结点中出现了两次,每个搜索码值都出现在某些叶子结点中,有的还在非叶子结点中重复出现。
在B+树中,搜索码值可能同时出现在非叶子结点和叶子结点中。与B+树不同,B树只允许搜索码值出现一次(如果它们是唯一的)。由于B树中搜索码不重复,因此可以用比相应B+树索引更少的树结点来存储索引。然而在B树中,由于出现在非叶子中的搜索码值不会出现在其他地方,因此我们将不得不在非叶子节点中为每个搜索码增加一个指针域。附加的这些指针指向文件记录或相应搜索码所对应的桶中。
B树叶子结点跟B+树叶子结点一样,不同在于非叶子结点 :
散列索引
借鉴Java HashMap的具体实现细节,通过仔细了解HashMap可以更加深入了解散列索引。在此推荐一篇讲述HashMap比较好的文章 Java HashMap工作原理及实现
位图索引

简单解释一下,在图中可以发现gender记录项只有m、f两个值,那么系统为这两个值分别建立一个位图,对于m位图来说,记录有多少,位图就有多少位,只有当第i个记录gender为m时,m位图的第i位为1,其他不是m的记录位全为零。概括的说,位图就是表示某一搜索码值出现在了哪些位置,通过遍历搜索码值的位图来查找,诸如下列SQL语句1
SELECT * FROM r WHERE gender = 'f'
这样的查询语句通过遍历f的位图是非常高效的。但是位图只是适用于搜索码值频繁出现,且选项少,这里所说的选项少是指比如记录人的性别只有三个选项:男、女、不知道,这样使用位图再适合不过了。通常情况下,位图可以和一般的B+树索引组合起来使用。
MySQL数据库几个基本的索引类型
- 普通索引 : 这是最基本的MySQL数据库索引,它没有任何限制。
- 唯一索引 : 它与前面的普通索引类似,不同的就是:MySQL数据库索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
- 主键索引 : 它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引。
- 组合索引 : 多字段建立索引。
视图
视图这么一个概念我一直不太准确理解,各种参考书上说得太正式,导致我越来越蒙。来我们看一看视图的定义:
Any relation that is not part of the logical model, but is made visiable to an user as a virtual relation, is called a view
翻译过来就是任何不是逻辑模型的一部分,但作为虚关系对用户可见的关系成为视图
在Database System Concepts这本书里面,作者通过一个例子来引出概念,这个例子如下:
当我们有一张表示银行中每个人借贷记录的表,我们需要知道这张表里面的部分信息,而不是全部信息,基于安全原因,我们会给用户透漏诸如借贷人姓名、借贷号,而不给用户透漏借贷量,我们就需要定义一个查询语句,只返回这张表的部分信息。此外我们可能需要其他的信息,而这些信息需要union多张表,但是这样的信息查询又是比较频繁的,我们也需要定义一个查询语句,来返回结果。
基于上述的例子,作者就引出了视图的概念。而我对于这个的理解是:我们需要基于两方面考虑,一个是安全性,当我们在使用mysql数据库的时候,数据库里面总是有一些视图表,里面包含了当前用户的所有数据库信息,诸如有哪些表,表里都有哪些属性这类信息。所有的可视范围在于当前用户的权限之内,权限之外就无法查看到,那么可以使用视图定义一个查询,根据用户权限,返回整个数据库中用户应该看到的东西。另一个考虑是简单性,我的理解是当我们需要较频繁进行一些查询时,我们总是要频繁的编写复杂的查询语句,为了简化,我们把这些频繁查询进行一定程度的封装,给用户展示一个简单的视图名,让用户能够直截了当的理解这个视图的作用,然后直接查询视图结果。
(这一段是我自己的理解,可能有误解)可能有人会这样选择,上述为了简化查询,为什么要使用视图,不直接使用新表,新表的构建通过其他表变化触发。如果我们使用表,那么我们可能要为每个频繁查找的语句创建一个合适的表,这样的后果是,数据库的表增多,而且表与表之间的关系更加复杂。虽然我们在学习数据库的时候常常让其遵守三范式,但这样会导致如果因为前期表的设计有问题,或者后期需要变化表,那么修改起来是一个非常巨大的工程,非常困难。相反视图并不在数据库中以存储的数据值集形式存在,修改起来是很方便的。
此外可能还有一个经常被问的问题是视图什么时候更新?因为视图是一种虚关系,所以是查询时更新,通俗一点就是,当底层的表有修改时,是去触发视图更新,还是当我们要用使用视图的时候更新。答案是后者,因为实质上视图还是一个查询语句,而不是表,每次使用视图,都需要重新执行视图定义的查询
事务
事务概念
事务是访问并可能更新各种数据项的一个程序执行单元。我们通常要求数据库系统维护事务的以下性质
- 原子性(Atom):事务的所有操作在数据库中要么全部正确反映出来,要么完全不反映。
- 一致性(Consistency):隔离执行事务时(换言之,在没有其他事务并发执行的情况下)保持数据库的一致性
- 隔离性(Isolation):尽管多个事务可能并发执行,但是系统保证,对于任何一对事务Ti和Tj,在Ti看来,Tj要么Ti开始之前已经完成执行,要么在Ti完成孩子后开始执行。因此,每个事务都感觉不到系统中有其他事务在并发地执行。
- 持久性(Durability):一个事务成功完成后,它对数据库的改变必须是永久的,即使出现系统故障。
这些性质通常成为ACID特性
事务隔离级别
- 可串行化(serializable) : 通常保证可串行化调度。然而正如我们将要解释的,一些数据库系统对该隔离性级别的实现在某些情况下允许非可串行化执行。
- 可重复读(repeatable read) : 只允许读取已经提交数据,而且在一个事务两次读取一个数据项期间,其他事务不得更新该数据。但该事务不要求与其他事务可串行化。
- 已提交读(read committed) : 只允许读取已提交数据,但不要求可重复度。比如在事务两次读取一个数据项期间,另一个事务更新了该数据并提交。
- 未提交读(read uncommitted) : 允许读取未提交数据。这是SQL允许的最低一致性级别。
乐观锁和悲观锁
为保持数据库事务的隔离性,系统必须对并发事务之间的相互作用加以控制。乐观并发控制(乐观锁)和悲观并发控制(悲观锁)是并发控制主要采用的手段。
- 乐观锁 : 假定不会发生并发冲突,只是在提交操作时检查是否违反了数据完整性。
- 悲观锁 : 假定会发生并发冲突,屏蔽一切可能违反数据完整性操作。
补充说明一下,对于悲观锁来说,如果一个事务操作对一个资源应用了锁时,其他事务只能等待该事务解锁后,再尝试对资源上锁。悲观锁主要用于数据争用激烈的环境,以及发生并发冲突时使用锁保护的成本低于回滚事务的成本环境中。
相对于悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发生冲突了,则返回用户错误的信息,让用户决定如何去做。
DELETE、DROP、TRUNCATE
- 想要彻底删除一张表时用drop
- 想要删除表中的部分数据用delete并带上where
- 想要删除表中数据而保留表用truncate
超键、候选键、主键、外键分别是什么
- 超键:在关系中能唯一标识元组的属性集。一个属性可以作为一个超键,多个属性组合在一起也可以作为一个超键
- 候选键:最小超键,即没有冗余的超键
- 主键:唯一表示一个元组的键,每个表只有一个主键,且主键不能为空
- 一个表中存这另一个表的主键,这个键被成为外键
三范式
- 1NF : 保证数据库表的字段不可再拆分,原子性
- 2NF : 不包括部分依赖,即没有属性只依赖主码的一部分
- 3NF : 表中不存在可以确定其他非关键字的非键字段
补充
1NF 消除非主属性对码的部分函数依赖就是 2NF
2NF 消除非主属性对码的传递函数依赖就是 3NF
3NF 消除了主属性对码的部分和传递函数依赖就是 BCNF
个人声明
由于文章里面的图片基本上都是在网上找的,所以可能会出现一段时间后,图片链接失效了,无法显示,如果出现这种情况,请给我留言!!!
谢谢!!!