分类问题
维基百科定义:分类问题是机器学习非常重要的一个组成部分,它的目标是根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类。分类问题也被称为监督式学习(supervised learning),根据已知训练区提供的样本,通过计算选择特征参数,建立判别函数以对样本进行的分类。 与之相对的称为非监督式学习(unsupervised learning),也叫做聚类分析。
数学定义:已知集合C = {y1,y2,...ym}和I = {x1,x2,...xn},确定映射规则y = f(x),使得任意xi ∈ I有且仅有一个yi ∈ C ,使得yi ∈ f(xi)成立。
在用户画像、NLP、预测、推荐等领域都需要研究分类问题。诸如NLP中情感分析,需要通过分类算法来分析文本的情感极性,这对于舆论监督有很好的帮助。
朴素贝叶斯分类算法综述
贝叶斯分类算法是一类算法的总称,这类算法都是以贝叶斯定理为基础,故统称贝叶斯分类算法。其中朴素贝叶斯分类算法是贝叶斯分类算法中最简单、最常见的一种分类方法。
贝叶斯分类算法核心便是概率论中的贝叶斯公式1
P(B|A) = P(A|B)P(B)/P(A)
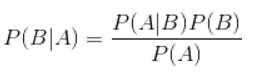
其中P(B|A)是指在事件A发生的情况下事件B发生的概率。
在贝叶斯定理中,每个名词都有约定俗成的名称:
- P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。
- P(A)是A的先验概率(或边缘概率)。之所以称为”先验”是因为它不考虑任何B方面的因素。
- P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
- P(B)是B的先验概率或边缘概率。
贝叶斯公式推导:
那朴素贝叶斯算法如何使用贝叶斯定理呢?将贝叶斯公式中的变量换成实体可有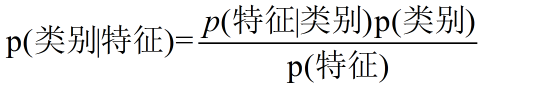
例子分析
给定如下苹果数据
| 编号 | 大小 | 颜色 | 形状 | 好吃 |
|---|---|---|---|---|
| 1 | 小 | 青色 | 非规则 | 否 |
| 2 | 大 | 红色 | 非规则 | 是 |
| 3 | 大 | 红色 | 圆形 | 是 |
| 4 | 大 | 青色 | 圆形 | 否 |
| 5 | 大 | 青色 | 非规则 | 否 |
| 6 | 小 | 红色 | 圆形 | 是 |
| 7 | 大 | 青色 | 非规则 | 否 |
| 8 | 小 | 红色 | 非规则 | 否 |
| 9 | 小 | 青色 | 圆形 | 否 |
| 10 | 大 | 红色 | 圆形 | 是 |
现在我在超市看见一个苹果又大又红又圆,现在预测好不好吃。那么分析成数学问题就是P(好吃|大、红、圆)与P(不好吃|大、红、圆)谁更大。1
2
3
4
5
6
7
8
9P(好吃|大、红、圆) = P(大、红、圆|好吃)P(好吃) / P(大、红、圆)
= P(大|好吃)*P(红|好吃)*P(圆|好吃)*P(好吃) / P(大、红、圆)
= (3/4) * (4/4) * (3/4) * (4/10) / P(大、红、圆)
= (144/640) / P(大、红、圆)
P(不好吃|大、红、圆) = P(大、红、圆|不好吃)P(不好吃) / P(大、红、圆)
= P(大|不好吃)*P(红|不好吃)*P(圆|不好吃)*P(不好吃) / P(大、红、圆)
= (3/6) * (1/6) * (2/6) * (6/10) / P(大、红、圆)
= (36/2160) / P(大、红、圆)
所有根据朴素贝叶斯算法计算得到在训练样本中P(好吃|大、红、圆)大于P(不好吃|大、红、圆),因此做出判断,又大又红又圆的苹果好吃。
根据上述计算过程可以发现,某个子属性的概率可能为0,例如 P(红|不好吃)可能为零,那么整个概率就为0。为了规避这个问题,在体量较大的样本训练中,为每一个子属性的样本数+1,在结果上的影响不大。
利用朴素贝叶斯对文本进行简单的情感分析
在网络环境中充斥着许多文本信息,此次情感分析问题细化到一个真实场景:当一个官方微博帐号发布了一则消息,官方希望能够通过程序自动分析出微博留言的情感與情。
问题分析
对问题进行分析,在这个问题中,程序需要获取的文本单位为一条留言,通常微博留言文本词量偏小,通常保持在50字以内。因此我们将每一条留言当作一个样本,我们只关心留言内容,对发表留言的时间、用户等属性不考虑,那么如何抽象文本信息属性呢?在留言中存在比较大量无效的停顿词,我们获取文本信息往往从关键的词语上获取,因此我们对文本进行关键词提取,然后组建一个留言的关键词向量,每个关键词都是文本的属性,由此我们就可以构建像上述例子的属性表,同时在训练样本中,我们根据自己的直觉对样本的每一条数据做个情感极性判断,主要的极性判断为消极情感和积极情感,然后利用朴素贝叶斯对测试样本进行分类。具体步骤如下:
- 下载微博留言数据
- 判断训练样本中每条留言的情感极性,并去除标点符号和特殊符号
- 利用HanLP对留言进行关键词提取,最多提取10个关键词
- 构建关键词与情感极性的稀疏矩阵(存在留言关键词不及10个的情况)
- 对测试样本进行关键词提取,利用贝叶斯公式分别计算两个情感极性的概率
- 将测试样本的情感极性归于概率较大的类别
问题过程示例
现在挑选皇族电子竞技俱乐部在2018年11月18日下午4点发布的一则微博的评论部分数据1
2
3
4
5
6
71. 加油加油!!
2. s8打的完全不配赢是真的,整个18年的努力和荣誉也是真的,吹rng牛逼是真的,骂rng辣鸡也是真的。 想再劈头盖脸骂一顿是真的,希望19年可以重拾荣耀也是真的。
3. RNG加油,面对未来的征程,皇族永不言弃。
4. 一次失利不是世界末日,如今深处低谷,冷眼和嘲笑难免,但请记得低头看看胸口的队名,勿言弃,勇前行!S9加油!
5. 假视频终于做好了,配合假语音,加上IG夺冠也把你们从风口浪尖的位置放下来了,是时候出来洗白了。我这一看评论全是rng加油,公关没少花吧?分给你们多少钱?香锅没人挡子弹的事那一段怎么播?语音在哪呢请告诉我?整这么一段花里胡哨的玩意有用?
6. 许少年1999:挨骂就挨骂吧。就好像你是家里最大的希望,高考却连二本都没上。挨骂是应该的,可是谁还不允许你复考了?RNG加油,RNG牛逼!
7. 明年的纪录片要彩色的!要最后大家一起喝彩的!要能让我笑着看完的!!!
对数据进行处理,获取每条留言的关键词,并构建稀疏矩阵
| 关键词 | 关键词 | 关键词 | 关键词 | 关键词 | 关键词 | 关键词 | 关键词 | 关键词 | 关键词 | 情感词性 |
|---|---|---|---|---|---|---|---|---|---|---|
| 加油 | 积极 | |||||||||
| 努力 | 荣誉 | 辣鸡 | 披头盖脸 | 重拾荣耀 | 牛逼 | 积极 | ||||
| 加油 | 未来 | 征程 | 皇族 | 用不言弃 | 积极 | |||||
| 失利 | 世界末日 | 深处 | 低谷 | 冷眼 | 嘲笑 | 胸口 | 队名 | 勿言弃 | 前行 | 积极 |
| 假 | 配合 | 风口浪尖 | 洗白 | 加油 | 公关 | 子弹 | 语音 | 花里胡哨 | 消极 | |
| 挨骂 | 希望 | 高考 | 二本 | 不允许 | 加油 | 牛逼 | 积极 | |||
| 明年 | 纪录片 | 彩色 | 喝彩 | 笑 | 积极 |
别问我为什么取的都是积极的。。。。。。我要保持积极!!!
然后对一条留言进行测试1
1. 你们接着打我就接着看!加油!我们等你! => [接着打,接着看,加油,等你]
再计算P(积极|接着打、接着看、加油、等你)和P(消极|接着打,接着看,加油,等你)并比较大小得出结论,1
2
3
4
5
6
7
8
9P(积极|接着打、接着看、加油、等你) = P(接着打、接着看、加油、等你|积极)*P(积极) / P(接着打、接着看、加油、等你)
= P(接着打|积极)*P(接着看|积极)*P(加油|积极)*P(等你|积极)*P(积极) / P(接着打、接着看、加油、等你)
= [(0+1)/(6)]*[(0+1)/(6)]*(3/6)*[(0+1)/(6)]*(6/7) / P(接着打、接着看、加油、等你)
= (18/9072) / P(接着打、接着看、加油、等你)
P(消极|接着打、接着看、加油、等你) = P(接着打、接着看、加油、等你|消极)*P(消极) / P(接着打、接着看、加油、等你)
= P(接着打|消极)*P(接着看|消极)*P(加油|消极)*P(等你|消极)*P(消极) / P(接着打、接着看、加油、等你)
= [(0+1)/1]*[(0+1)/1]*(1/1)*[(0+1)/1]*(1/7) / P(接着打、接着看、加油、等你)
= (1/7) / P(接着打、接着看、加油、等你)
这不是打脸了吗?仔细分析,问题有两个,第一我们选取的样本中消极太少权重太小,单条记录对结果影响太大,因此对训练样本的选取很重要;第二,我们所选择的总样本数量太少,而这样的文本分析应该是基于大数据来分析的
问题
在关键词提取后,仍然发现有诸如[高考,皇族,队名,配合]等词语对情感极性判断没有太大的影响,但会在一段时间高频出现,如果将这些词与真正表示情感的词化作同等权重来计算,也会影响计算结果。
解决办法:构建一个情感词权重词典,通过词典对关键词向量进行二次特征提取,以求获取更加精准的判断效果
面对大数据文本时人为判断训练样本的情感词极性是一个繁重的活
这是文本分析比较普遍的问题,有效样本越多,算法结果越精准。但是我们可以谨慎选择一个比较合理的基础训练样本,计算未知样本的情感极性,分类结束后,我们将样本加入到训练样本中,迭代式的增加样本数量。为什么说是谨慎的选择呢,从上面的例子可以看到,原本的基础训练样本影响到后面添加进来的样本,如果基础训练样本不合理,随着迭代次数的增加,整个训练样本会越来越不合理。
在大数据集上的计算困难,利用原始的方式非常困难
利用现有的文本引擎工具
Elasticsearch能够很好的解决这个问题。在这个问题分析过程中,我们默认了我们使用的HanLP关键词提取能够提取到我们想要的关键词,但事实关键词提取也是一个非常困难的问题,对这类的研究也很复杂,而我们的情感分析的准确度也高度依赖关键词提取效果。
HanLP的分词、关键词提取也高度依赖了背后的分词词典,随着网络信息传播,往往会出现新的词汇,我们需要定时的收集新词汇,添加到HanLP的分词字典中(可以想要这个要求是很合理的,我们在理解网络词汇的时候也是不断学习的,因此没有理由让分词词典一成不变)
Elasticsearch
Elasticsearch是NLP研究过程中非常强大的工具,它类似关系性数据库,拥有数据库(index),数据库中有表(type),表上有属性(字段)。但是不同的是Elasticsearch可以为每个字段建立的索引,这个索引不同于mysql的B+树,而是倒排索引,这个索引记录一个字段的所有直,并记录每个值出现在那些记录里里面。在我们使用朴素贝叶斯计算时,想要获取某个条件下的概率,只需要编写简单的查询语句就可以得出结果,而这个搜索引擎可以在PB级数据量上进行秒级查询。
Elasticsearch索引设计: 提取留言文本关键词,关键词作为一条记录的字段名,字段名的值为情感权值,同时还有一个训练样本的感情极性字段,例如s8打的完全不配赢是真的,整个18年的努力和荣誉也是真的,吹rng牛逼是真的,骂rng辣鸡也是真的。 想再劈头盖脸骂一顿是真的,希望19年可以重拾荣耀也是真的。的存储模式为:1
{id:1, 努力:4, 荣誉:2,辣鸡:1/4,披头盖脸:1/2,重拾荣誉:2,牛逼:2,极性:"积极"}
请注意当一个词语对最后的情感结论是负作用,那么这个词根据情感词典的权值取权值的倒数
对一条测试样本,测试样本如上述步骤进行关键词提取,通过Elasticsearch查询语句获取贝叶斯定理中的概率,计算积极和消极概率得出结论。(得出结论后也可以将新样本加进训练样本)
朴素贝叶斯分类算法的优缺点
优点
- 对大数量训练和查询时具有较高的速度。即使使用超大规模的训练集,针对每个项目通常也只会有相对较少的特征数,并且对项目的训练和分类也仅仅是特征概率的数学运算而已。
- 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
- 支持增量式运算。即可以实时的对新增的样本进行训练。
- 朴素贝叶斯对结果解释容易理解。
缺点
- 由于使用了样本属性独立性的假设,所以如果样本属性有关联时其效果不好。
- 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
- 由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。