决策树简介
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。 数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。
决策树学习也是数据挖掘中一个普通的方法。在这里,每个决策树都表述了一种树型结构,它由它的分支来对该类型的对象依靠属性进行分类。每个决策树可以依靠对源数据库的分割进行数据测试。这个过程可以递归式的对树进行修剪。 当不能再进行分割或一个单独的类可以被应用于某一分支时,递归过程就完成了。
在分类算法中,决策树每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
实例说明
问题描述:目前抽取了西瓜的部分属性,包括[纹理,根蒂,触感,色泽],并挑选了部分西瓜,对每个西瓜的属性进行记录,现在希望通过之前的西瓜样本,构建出一个经验决策树,能够判断一个西瓜是否好吃。
决策树如何构建
这个问题可以换个方式考虑,在决策树简介中的那棵决策树中,为什么我们首先判断西瓜的纹理,在左子树中为什么先判断根蒂而在右子树中判断触感。为了解释这个问题,需要引出一个新的概念信息熵,一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件不确定的事,需要了解大量信息。熵(entropy)用于表示随机变量不确定性的度量, 如果熵越大,表示不确定性越大。
假设变量X,它有Xi(i=1,2,3…n)种情况,pi表示第i情况的概率,那么随机变量X的熵定义为: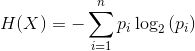
比如当随机变量X只有0,1两种取值,则有: H(x) = -plog(p) - (1-p)log(1-p) , 可以画出一个二维坐标表示他们的关系: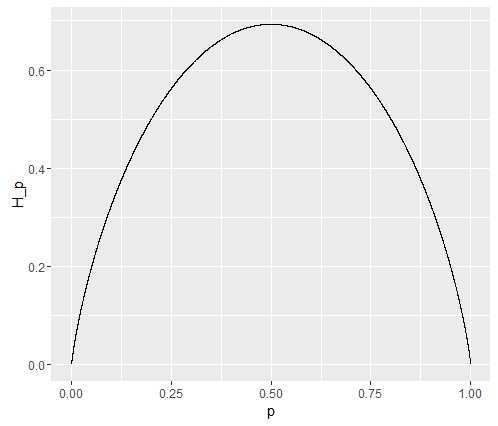
从而可知,当 p=0.5 时,熵取值最大,随机变量不确定性最大。从常识上可以解释为,当只有两种可能时,当两种可能概率相同,我们就很难判断哪个事件会发生,而如果其中有一个概率非常小,另一个概率非常大,那么我们就有很大的把握去判断大概率事件会发生。前者是不确定性大,后者是确定性大。
由此继续延伸条件熵:随机变量X给定的条件下,随机变量Y的条件熵 H(Y|X) 定义为
信息增益:得知特征X的信息而使得分类Y的信息的不确定性减少的程度。如果某个特征的信息增益比较大,就表示该特征对结果的影响较大,特征A对数据集D的信息增益表示为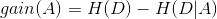
我们通过西瓜的数据分别解释每个概念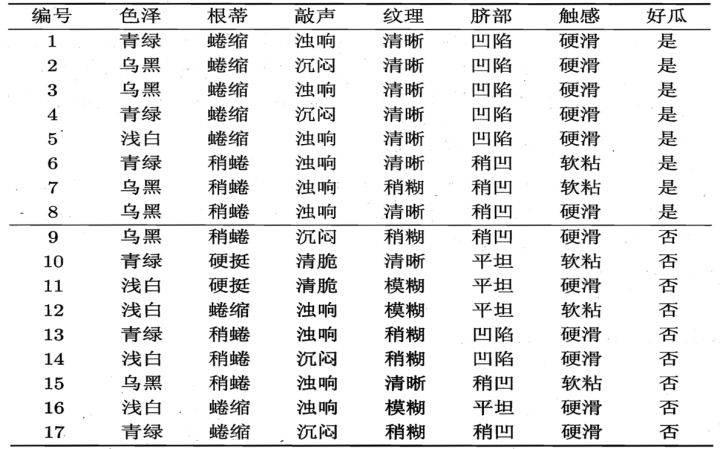
信息熵:info(D) = -P(是)logP(是) - P(否)logP(否) = I(8,9)条件熵:info(D|纹理) = P(清晰)I(7,2) + P(稍糊)I(1,5) + P(模糊)I(0,3)信息增益:gain(纹理) = info(D) - info(D|纹理)
决策树归纳算法(ID3)构建决策树
ID3算法的核心是在决策树的各个结点上应用信息增益准则进行特征选择。具体做法是:
- 从根节点开始,对结点计算所有可能特征的信息增益,选择信息增益最大的特征作为结点的特征,并由该特征的不同取值构建子节点;
- 对子节点递归地调用以上方法,构建决策树;
- 直到所有特征的信息增益均很小或者没有特征可选时为止。
递归划分步骤仅当下列条件之一成立停止: (a) 给定结点的所有样本属于同一类。 (b) 没有剩余属性可以用来进一步划分样本。在此情况下,使用多数表决。这涉及将给定的结点转换成树叶,并用样本中的多数所在的类标记它。替换地,可以存放结点样本的类分布。 (c) 分枝,当所有特征的信息增益都很小,也就是没有再计算的必要了,就创建一个树叶,也是用多数表决。
ID3基于信息增益的概念,但算法存在一定的问题,如果某个属性取值很多时条件熵就会很小,在递归构建决策树时选择决策属性会很麻烦,多个属性之间的信息增益没有显著的数量级上的差距,此时选取最大值往往是一种赌博。此外如果属性是比较连续的值,ID3的方法是不同的值分开计算,这是ID3的缺点,可以改进的方法是按照一定的规律划定一定的区间,一个区间看作一种属性值。针对决策树,还有许多改进的方法去更好的构建决策树,诸如C4.5等,这里不做细讲。
决策树的优缺点
- 优点
- 决策树易于理解和解释,可以可视化分析,容易提取出规则。
- 可以同时处理标称型和数值型数据。
- 测试数据集时,运行速度比较快。
- 决策树可以很好的扩展到大型数据库中,同时它的大小独立于数据库大小。
- 缺点
- 对缺失数据处理比较困难。
- 容易出现过拟合问题。
- 忽略数据集中属性的相互关联。
- ID3算法计算信息增益时结果偏向数值比较多的特征。